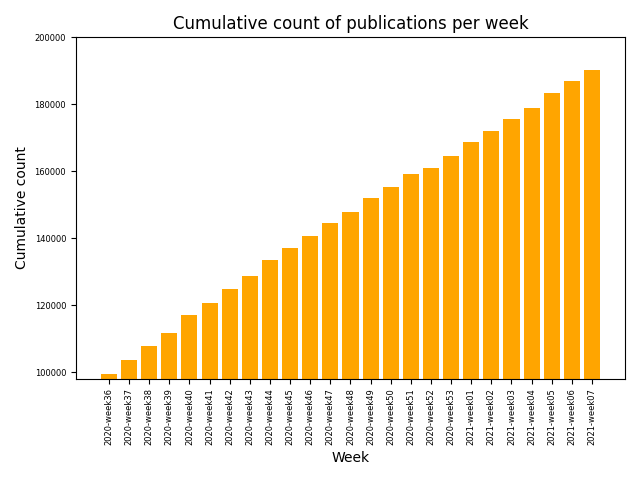
Aktuell wächst die Anzahl wissenschaftlicher Publikaitonen zu SARS-CoV-2- und COVID-19 mit exponentieller Geschwindigkeit an; die daraus resultierende Informationsflut wird für den Menschen praktisch unüberschaubar. Angesichts der Notwendigkeit, relevante Literatur zu identifizieren und zu strukturieren, ist ein zunehmendes Angebot an Datenbanken mit COVID-19-bezogener Literatur zu beobachten. Die automatisierte Verwaltung und Erweiterung dieser Dokumentensammlungen - auch Korpora genannt - bildet die Grundlage für weitere Text-Mining-Anwendungen.
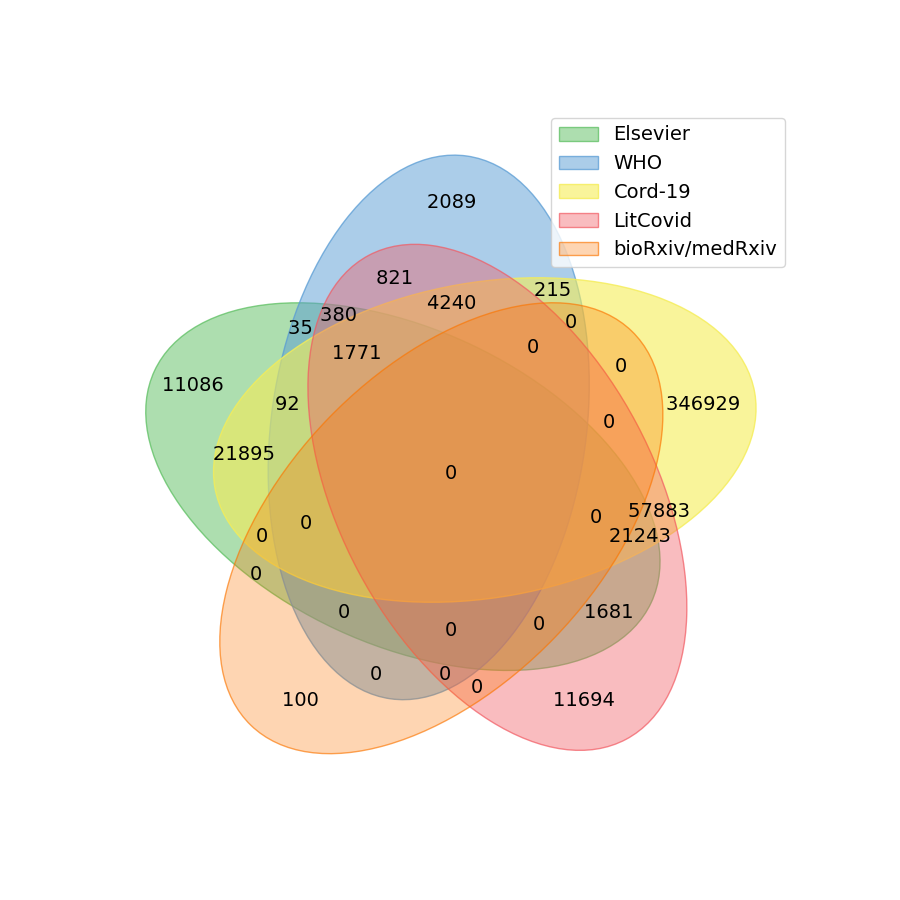
Gegenwärtig sammeln und aktualisieren mehrere Organisationen Korpora mit Bezug zu COVID-19. Diese enthalten oft das Textdokument mit Metadaten (wie Publikationsdaten, Autorenliste, PubMed-IDs, DOIs). Einige der frei verfügbaren Korpora sind nachstehend aufgeführt:
- LitCovid wird vom National Institute of Health (NIH), USA, zur Verfügung gestellt und klassifiziert die Dokumente manuell in Klassen wie allgemeine Informationen, Mechanismen, Diagnose, Übertragung.
- WHO COVID-19 corpus kategorisiert ebenfalls die relevante Literatur.
- COVID-19 Open Research Dataset (CORD-19) wurde vom Allen Institute For AI et al. gegründet und stellt wissenschaftliche Literatur für Textminer und Datenwissenschaftler zur Verfügung.
- COVID-19-bezogene medRxiv/bioRxiv Preprints: bietet Wissenschaftlern eine Plattform zur Veröffentlichung von Forschungsergebnissen ohne vorheriges Peer-Review.
- Elsevier’s Coronavirus Information Center beinhaltet biologische und medizinische Forschung zu SARS-CoV-2 und COVID-19.
Darüber hinaus stehen Volltexte für das Elsevier-Korpus, die medRxiv- und bioRxiv-Preprints sowie das CORD-19-Korpus zur Verfügung, die wir in unsere Literatur-Mining-Plattform SCAIView integrieren. Weitere nennenswerte Ressourcen sind die Dimensions Literature Database und die Cochrane Special Collections.
Auf der Grundlage der verfügbaren Abstracts, die in den zusammengeführten Datenbanken zur Verfügung gestellt werden, bieten unüberwachte Themenmodellierungsansätze wie Latent Dirichlet Allocation (LDA) Einblicke in verschiedene Themen, die von den Korpora abgedeckt werden. Durch die Verwendung von Themen-Tags, die z.B. im LitCovid-Korpus zur Verfügung gestellt werden, ist es außerdem möglich, einen Dokumentenklassifikator zu trainieren, der zur Kategorisierung neuer COVID-19-bezogener Literatur verwendet werden kann. In naher Zukunft ist es das Ziel, kontinuierlich weitere Ressourcen und mehr Volltextsammlungen zu integrieren und dadurch die bestehenden Text-Mining-Ansätze zu validieren und zu erweitern.